Ever wondered how predicting the future at every stage of our lives will make our lives so convenient? Because what we don’t realise is, our life is filled with patterns.
Won’t it be great to analyse these already existing patterns to make our lives easier? Well, don’t worry, Data Mining has got you covered. Data mining is the exploration and analysis of large data to discover meaningful patterns and rules.
There are various types of Data Mining techniques available. The one which seems to be the most naive yet powerful is Apriori Algorithm.
a priori; a Latin word, literally means ‘from what is before’. Hence Apriori Algorithm is an efficient way of Data Mining where the most frequent itemsets and association rules for a transactional database can be identified. Wait, did that confuse you? Don’t worry because that’s why we are here.
Let’s take one step at a time.
What are Association Rules?
The rules devised during the process of Associate Rule Mining (ARM) are called Associate Rules.
Being an integral part of Data Mining, ARM helps us create simple IF/THEN rules statements that help discover relationships and patterns between items in the database, and to consequently predict the next item set. The biggest application of ARM in today’s world is business decisions and analytics.
In layman’s language, it is the creation of rules such as IF a customer purchases a product A THEN the customer is also likely to purchase product B.
In technical terms, such a product A is called an Antecedent (IF), and product B an Consequent (THEN).
But if determining such a IF/THEN relationship was so simple, why would we need the Apriori Algorithm? The answer lies in the fact that for a single product A, there are probably 9999 such products B, which hold some sort of resemblance. Apriori aims to solve this exact problem.
The Algorithm Explained
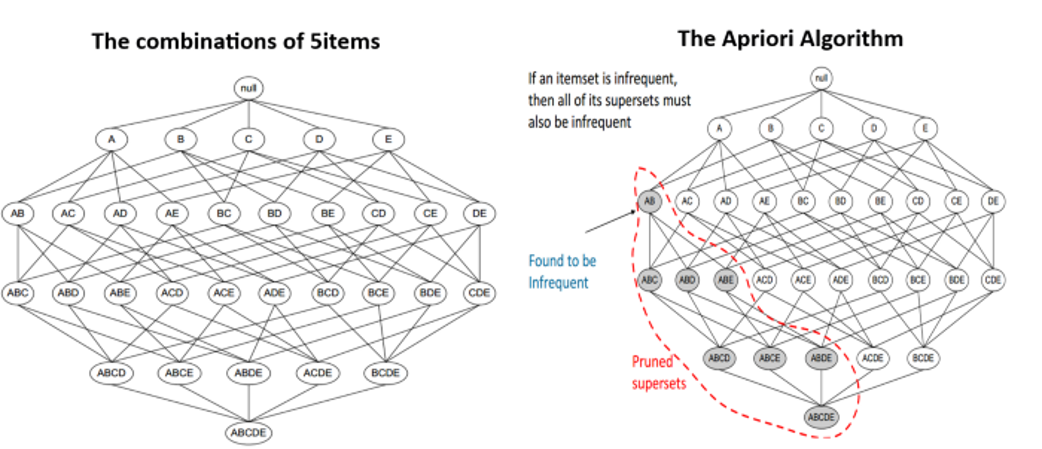
Apriori algorithm uses frequent itemsets to generate association rules. It is based on the concept that a subset of a frequent itemset must also be a frequent itemset. Items in a transaction form an item set. The algorithm proceeds to find frequent itemsets in the database and continues to extend them until it reaches the threshold. Frequent Itemset is an itemset whose support value is greater than a threshold value.
The apriori algorithm uses the downward closure property ,i.e., all the subsets of a frequent itemset are frequent, but the converse may not be true.
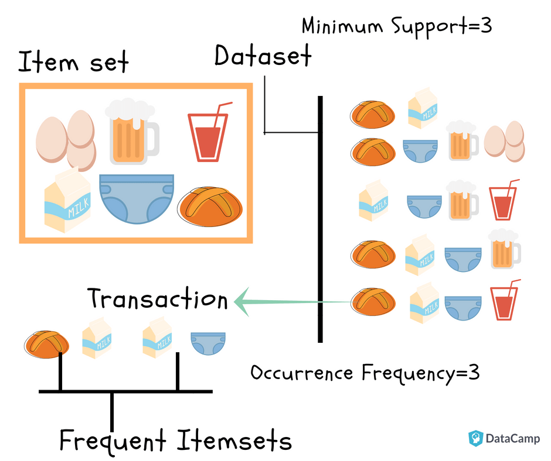
But this was just the intuition, how do things actually work?
Let’s dive into the mathematics of the algorithm, and for which we will need to know 3 important terms
- Support
- Confidence
- Lift
Support:
Support basically refers to the number of times the chosen item/s appears in the database, i.e the frequency of the item/s. Having said this, it is quite easy to guess it’s formula,
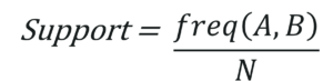
Where freq(A,B) denotes the frequency of A and B appearing together in a transaction, and N denotes the total number of items in the database.
Confidence:
Remember the concept of Conditional Probability from highschool? Let’s revise it again.
Conditional Probability refers to a special type of probability where an event will occur, given a particular event has already happened. This is exactly what confidence is. In other words, Confidence refers to the frequency of A and B being together, given the number of times A has occurred.
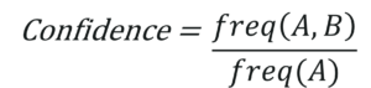
Lift:
The lift of a rule is defined as:
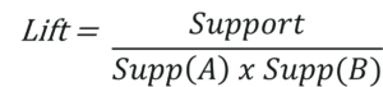
This signifies the likelihood of the itemset B being purchased when item A is purchased while taking into account the support of B
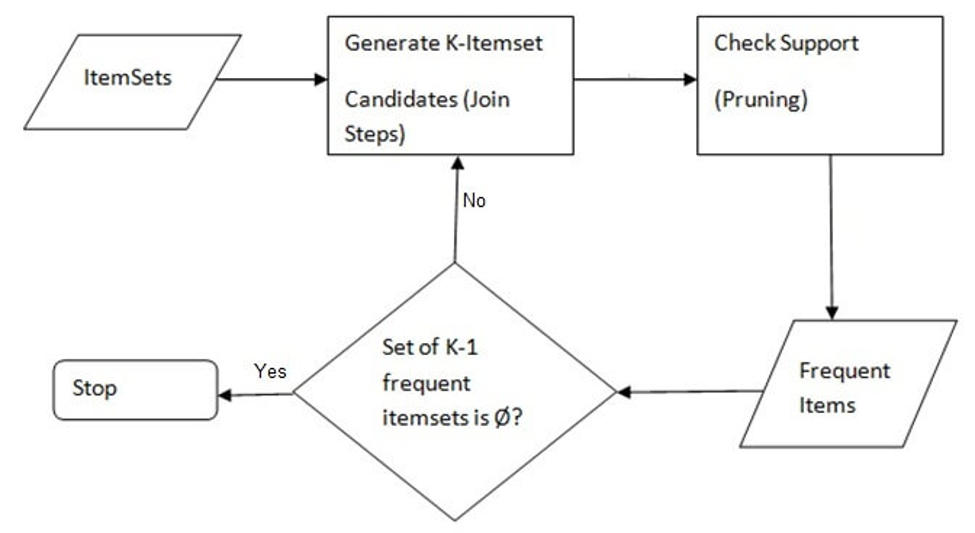
The main steps involved in the algorithm are:
- Calculate the support (frequency) of item sets (of size K = 1) in the transactional database. This is called generating the candidate set.
- Prune the candidate set by eliminating items with a support less than the given threshold. Pruning basically means eliminating the itemsets which are not necessary, hence refining the itemsets.
- Join the frequent itemsets to form sets of size k + 1, and repeat the above sets until no more itemsets can be formed. This will happen when the set(s) formed have a support less than the given support.
That was a lot of theory! Let’s now have a look at the most popular use case of the Apriori Algorithm, Market Basket Analysis.
Market Basket Analysis
The approach is based on the hypothesis that customers who buy a certain item (or group of items) are more likely to buy another specific item (or group of items).
Wait, is it just me, or does this sound very much similar to Apriori? Infact, Market Basket Analysis is entirely based on the Apriori algorithm itself.
The relations hence can be used to increase profitability through cross-selling,
recommendations, promotions, or even the placement of items on a menu or in a store.
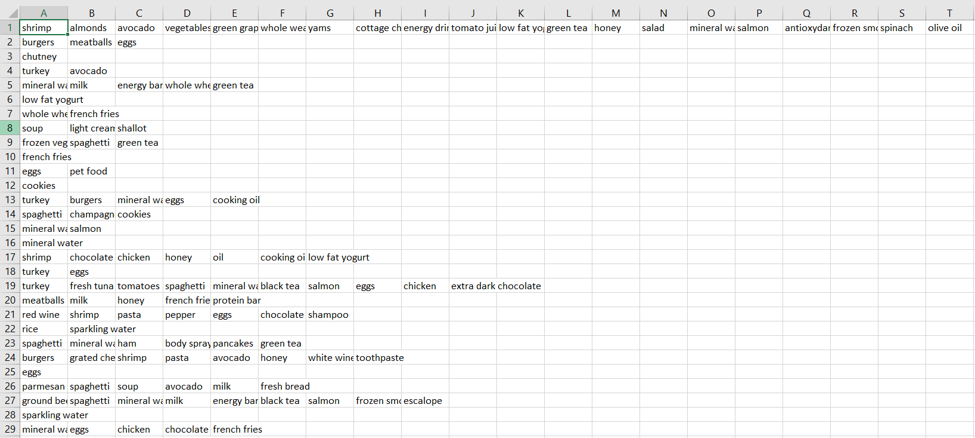
Understanding our used case:
For the implementation of Apriori algorithm, we are using data collected from a SuperMarket, where each row indicates all the items purchased in a particular transaction.
The dataset has 7,500 entries .
The link to the dataset -
https://drive.google.com/file/d/1nGzgX2cq8R4AT-9cMq_puzB1XgPnb6Pf/view?usp=sharing
Python Implementation
STEP 1: Let’s install the apyori module.
Apyori is a simple implementation of Apriori algorithm with Python 2.7 and 3.3 - 3.5, provided as APIs and as command-line interfaces.

STEP 2: We import the necessary libraries required for the implementation.
STEP 3: Reading the dataset
Now we have to proceed by reading the dataset we have , that is in a .csv format. We do that using pandas module’s read_csv function.
The apyori module’s apriori function takes primary input in a list format. For this purpose, we first create an empty list named ‘transactions’.
Iterating through all our rows, i.e. 7500 entries, we append each of the values of the row after converting all the inputs into a string.
The inner loop is of range(0,20) , as we have maximum 20 values in a particular row entry. For other rows having less than 20 values, we automatically consider the remaining as null inputs.

STEP 4: We import the apriori function from the apyori module. We store the resulting output from apriori function in the ‘rules’ variable.
To the apriori function, we pass 6 parameters:
- The transactions List as the main inputs
- Minimum support, which we set as 0.003 We get that value by considering that a product should appear at least in 3 transactions in a day. Our data is collected over a week. Hence , support value should be 3*7/7500 = 0.0028
- Minimum confidence, which we choose to be 0.2 (obtained over analyzing various results)
- Minimum lift, which we’ve set to 3
- Minimum Length is set to 2, as we are calculating the lift values for buying an item B given another item A is bought, so we take 2 items into consideration.
- Minimum Length is set to 2 using the same logic.

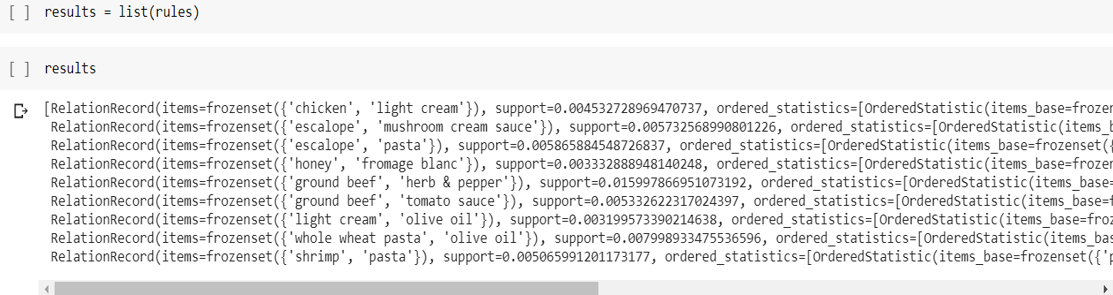
STEP 5: We print out the results as a List
STEP 6: Visualizing the results
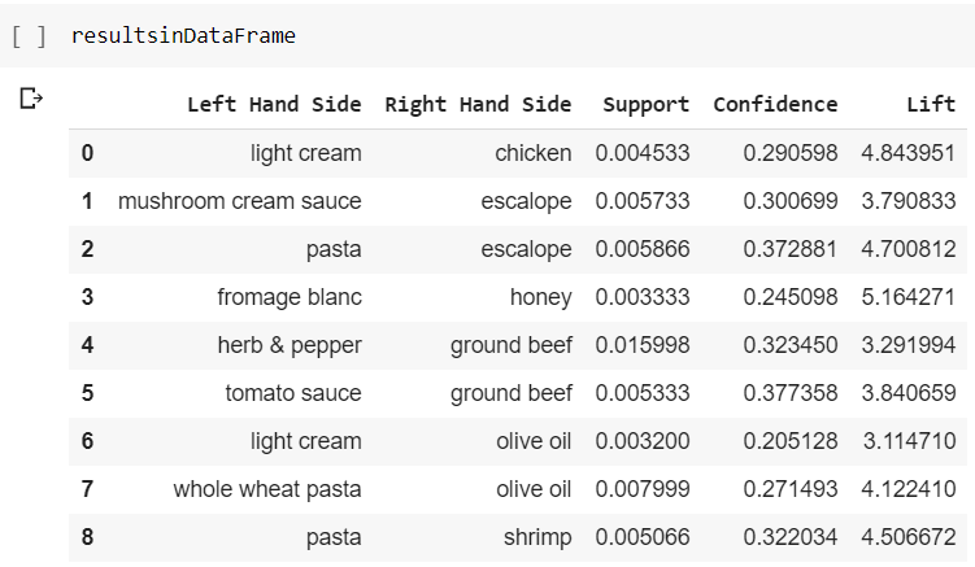
In the LHS variable, we store the first item from all the results, from which we obtain the second item that is bought after that item is already bought, which is now stored in the RHS variable.
The supports, confidences and lifts store all the support, confidence and lift values from the results.

Finally, we store these variables into one dataframe, so that they are easier to visualize.
Now, we sort these final outputs in the descending order of lifts.
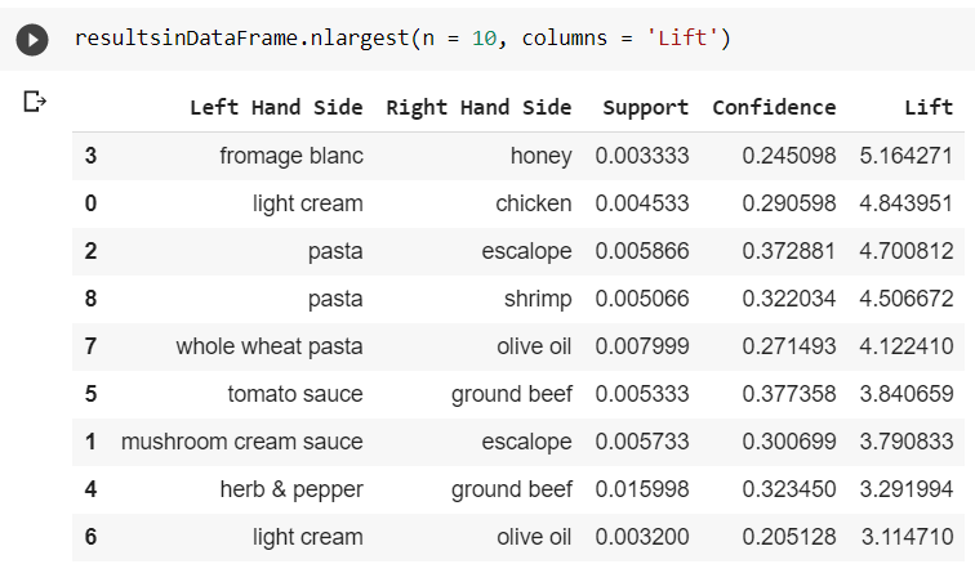
This is the final result of our apriori implementation in python. The SuperMarket will use this data to boost their sales and prioritize giving offers on the pair of items with greater Lift values.
Why Apriori?
- It is an easy-to-implement and easy-to-understand algorithm.
- It can be easily implemented on large datasets.
Limitation of Apriori algorithm
Frequent Itemset Generation is the most computationally expensive step because the algorithm scans the database too many times, which reduces the overall performance. Due to this, the algorithm assumes that the database is Permanent in the memory.
Also, both the time and space complexity of this algorithm are very high: O(2^{|D|}), thus exponential, where |D| is the horizontal width (the total number of items) present in the database.
A common mistake
Association involves analysing the underlying patterns in the given transactions in all possible ways, whereas
Recommendation is the process of predicting the possible outcome based on the individual transaction history of the consumer.
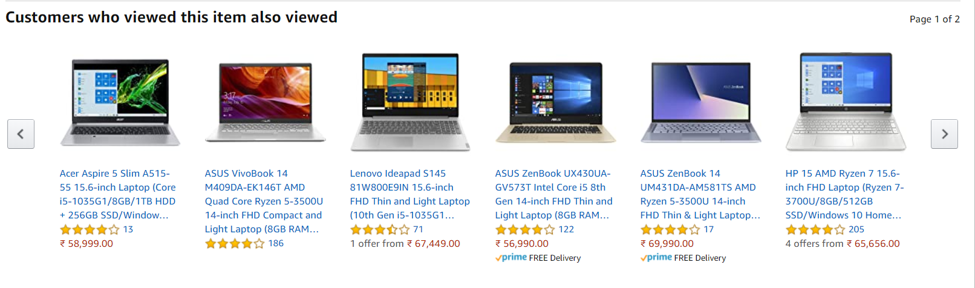
To understand it better, take a look at the snapshot below from amazon.in and flipkart.in and you will notice 2 headings “Bought Together” and the “Customers who viewed this item also viewed” on each product’s information page.
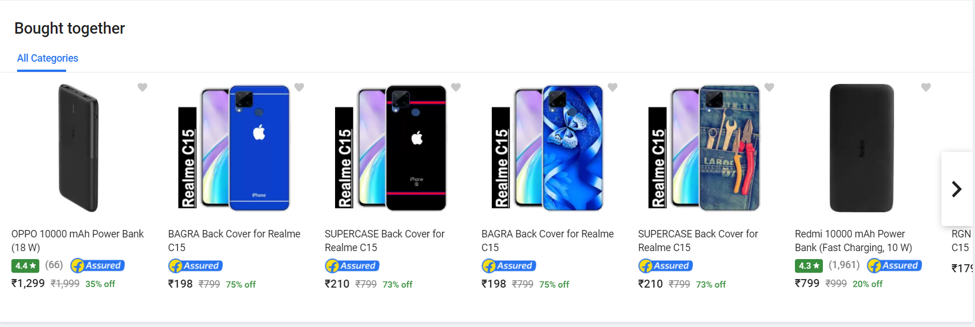
Bought Together shows the associative results.
Customers who viewed this item also viewed gives us the recommendations.
Summary

Apriori Algorithm is an unsupervised learning technique which aims at associating items from a transactional database to give us rules which will predict the buying/occurrence patterns. The flowchart above will help summarise the entire working of the algorithm.